
Data modeling merupakan sebuah keahlian yang penting bagi tim data, baik itu data engineer ataupun data analyst. Data modeling menentukan arsitektur data dan arah kerja yang akan digunakan oleh seluruh tim data. Walaupun bukan merupakan topik yang baru, data modeling masih sangat relevan untuk dibahas dan dipelajari, bahkan pada era big data saat ini.
Data modeling adalah proses abstraksi data yang bertujuan untuk menggambarkan dan memahami bagaimana data diorganisir dan bagaimana berinteraksi dengan data. Dengan demikian, data modeling membantu dalam membangun landasan yang kokoh untuk struktur basis data, yang menjadi tulang punggung aplikasi bisnis modern, analisis data, dan implementasi sistem informasi yang efisien.
Dalam artikel ini akan dibahas secara sepintas mengenai beberapa teknik data modeling seperti Normalized Modeling (Bill Inmon), Denormalized Modeling (Ralph Kimball), Data Vault 2.0 dan One-Big-Table (OBT).
Mengapa Data Modeling Penting?
Data modeling adalah salah satu aspek yang sangat penting dalam manajemen data modern. Data modeling merupakan proses penting dalam membentuk landasan bagi desain struktur database yang efisien, sistem informasi yang baik, dan analisis data yang akurat.
Beberapa alasan mengapa data modeling menjadi faktor yang penting, diantaranya adalah
1. Data Berasal Dari Berbagai Sumber
Strategi pemodelan data yang efektif sangat penting untuk mengelola dan mengintegrasikan data dari berbagai sumber. Baik yang berasal dari database, API, spreadsheet, maupun repositori data lainnya. Pendekatan pemodelan data yang kuat dapat memastikan bahwa informasi dari berbagai sumber tersebut dapat ditransformasi dan diintegrasikan dengan baik.
2. Banyaknya Pengguna Data
Membuat data untuk dapat diakses dengan mudah oleh semua pengguna data merupakan tantangan tersendiri. Semakin banyak orang dan pihak yang menggunakan data, pemodelan data semakin dibutuhkan untuk memastikan semuanya tetap terstruktur dan berfungsi dengan baik untuk tiap pengguna.
3. Performa dan Efisiensi
Pemodelan data yang baik dapat membuat data lebih cepat ditemukan dan digunakan dengan segera. Performa disini tidak hanya menyangkut kecepatan akses, tetapi juga mempertimbangkan efisiensi biaya. Data yang teroptimasi dapat menghemat waktu dan sumber daya. Hal ini tentu saja dapat membantu menghemat biaya pengelolaan dan penyimpanan data.
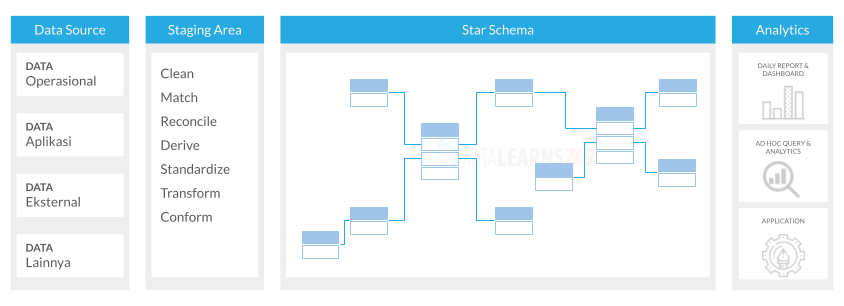
Denormalized Modeling (Ralph Kimball)
Denormalized model dikenal juga sebagai dimensional modeling yang menerapkan star schema atau snowflake schema. Teknik pemodelan data ini dikembangkan oleh Ralph Kimball.
Pada dasarnya, data dibagi menjadi dua jenis tabel, yaitu fact table dan dimension table. Fact table menyimpan data kuantitatif, seperti transaksi penjualan, pendapatan, atau user click. Sedangkan tabel dimensi menyimpan data deskriptif, seperti produk, pelanggan, atau tanggal.
Fact table dihubungkan ke dimension table oleh foreign keys, dan membentuk struktur seperti bintang atau snowflake. Model dimensi dirancang untuk mengoptimalkan performa dan penggunaan analisis dan pelaporan data dengan menyederhanakan operasi join, kueri, dan memberikan struktur data yang konsisten dan intuitif.
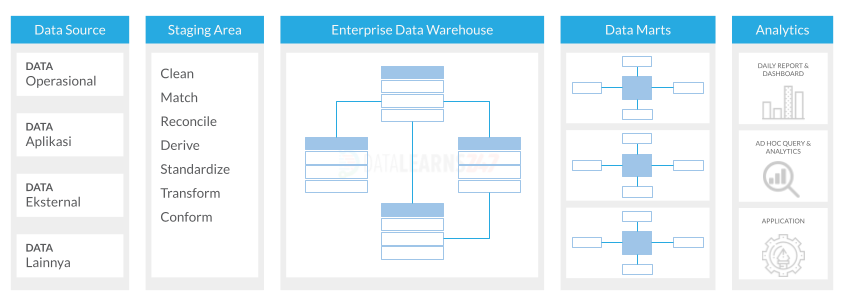
Normalized Modeling (Bill Inmon)
Normalized modeling adalah teknik pemodelan data yang diperkenal dan dan dikembangkan oleh Bill Inmon. Teknik ini mengimplementasikan model relasional dalam sebuah Enterprise Data Warehouse (EDW).
Pada prinsipnya teknik ini menerapkan normalisasi data dengan membagi data menjadi beberapa tabel dengan meminimalisir duplikasi data dan memaksimalkan integrasi data. Model yang dinormalisasi dirancang untuk mengoptimalkan kualitas dan konsistensi data dengan menghindari duplikasi data, memastikan keakuratan data, dan memfasilitasi integrasi dan pemeliharaan data.
Normalized modeling biasanya diimplementasikan sebagai tempat penyimpanan data terpusat dan terstandarisasi. Data-data ini akan dianggap sebagai Single Source of Truth atau data yang dianggap paling benar dalam sebuah organisasi.
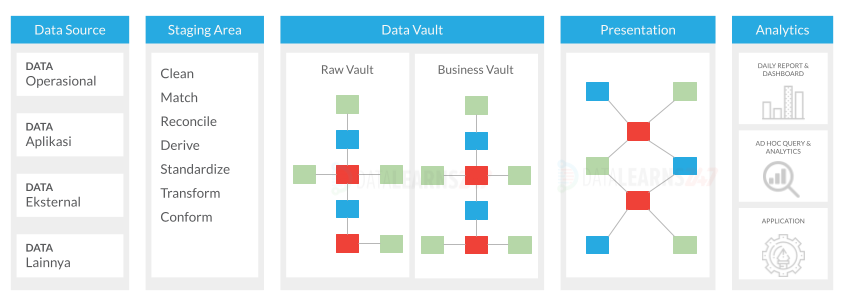
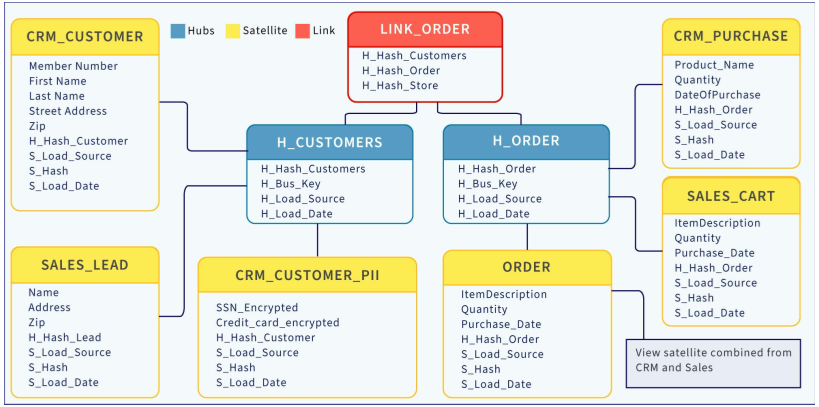
Data Vault 2.0
Data Vault 2.0 merupakan evolusi dari teknik Data Vault sebelumnya. Data Vault pertama kali dikembangkan oleh Dan Linstedt pada tahun 2000. Data vault adalah data modeling design pattern yang digunakan untuk membangun platform data respons terhadap perkembangan teknologi dan kebutuhan bisnis yang semakin kompleks dalam mengelola data. Data vault adalah data modeling design pattern yang digunakan untuk membangun platform data respons terhadap perkembangan teknologi dan kebutuhan bisnis yang semakin kompleks dalam mengelola data.
Data vault memiliki tiga jenis entitas, yaitu hub, link, dan satellite.
- Hub: Setiap hub mewakili konsep bisnis inti, seperti id pelanggan atau nomor produk. Pengguna akan menggunakan kunci bisnis (business key) untuk mendapatkan informasi tentang Hub. Kunci bisnis mungkin memiliki kombinasi ID konsep bisnis dan ID urutan, tanggal pemuatan, dan informasi metadata lainnya.
- Link: mewakili hubungan antar entitas Hub.
- Satellite: Satelit mengisi kekurangan dalam menjawab informasi deskriptif yang hilang mengenai konsep bisnis inti. Satellite menyimpan informasi milik Hub dan hubungan di antara mereka.
Saat bekerja dengan Data Vault, yang harus diingat adalah:
- Sebuah Satellite tidak dapat memiliki koneksi langsung ke Satellite lain.
- Sebuah Hub atau Link mungkin memiliki satu atau lebih Satellite.
Data Vault adalah teknik data modeling yang cocok bagi mereka yang mengadopsi paradigma lakehouse.
One-Big-Table (OBT)
Pemodelan data One-Big-Table terdengar seperti bukan sebuah konsep atau teknik pemodelan data yang serius. One-Big-Table adalah tabel yang mencoba menampung semuanya. Teknik ini bertujuan untuk menyederhanakan dan mempercepat integrasi data dengan menggabungkan semua data mentah dari berbagai sumber ke dalam satu tabel besar (one big table)
Sesuai dengan namanya, One-Big-Table mengacu pada penggunaan satu tabel untuk menampung semua data dalam satu tabel besar. Pendekatan ini memastikan tidak perlunya untuk melakukan operasi join. Karena kesederhanaannya, OBT cocok untuk tim kecil dan proyek kecil yang berfokus pada pelacakan item tertentu. Item ini biasanya memiliki beberapa atribut yang terkait dengannya.
Misalnya, jika kita ingin menggunakan data warehouse untuk analisis pelanggan, OBT akan difokuskan pada “pelanggan” dengan atribut seperti ID pelanggan, nama, usia, dll.
Pendekatan ini dapat menawarkan beberapa keuntungan, termasuk dalam hal pengelolaan data yang jauh lebih sederhana, kinerja kueri yang lebih cepat, dan skalabilitas yang lebih mudah. Namun, hal ini juga dapat menimbulkan tantangan dalam hal pemodelan data, pengindeksan, dan konsistensi data.
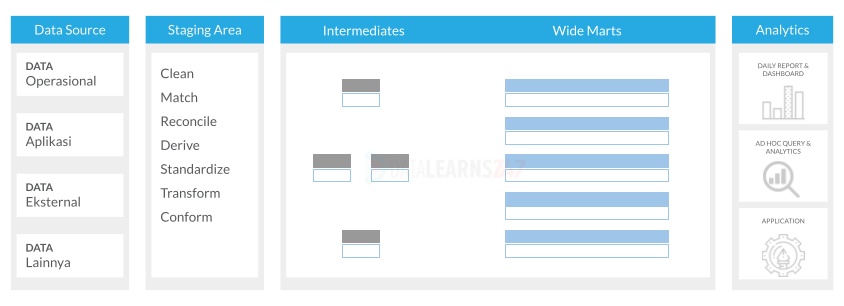
Wrapping Up
Dalam era di mana data menjadi aset yang semakin berharga dan vital bagi perusahaan, teknik pemodelan data memainkan peran yang sangat penting dalam mengelola, mengorganisir, dan menggali potensi dari informasi yang tersimpan. Pemodelan data yang baik membantu kita memahami dan mengoptimalkan manfaat dari semua data yang kita miliki.